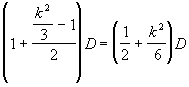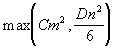![]()
![]()
![]()
![]()
Επόμενο:9.4 Αλγόριθμος JACOBI Πάνω: Κεφάλαιο 9o : Επιμερισμός δεδομένων Πίσω: 9.2 Το Πρόβλημα των Ν-Σωμάτων στην Αστροφυσική
9.3 Πολλαπλασιασμός Μήτρας
Οι επιστημονικοί υπολογισμοί έχουν σχέση με μεγάλους πολυδιάστατους πίνακες αριθμών (μήτρες της γραμμικής άλγεβρας). Το πρόβλημα του πολλαπλασιασμού δύο μητρών είναι σύνηθες σε τέτοιου είδους εφαρμογές. Ο πολλαπλασιασμός μητρών μπορεί να εκφραστεί με μια απλή υπολογιστική διαδικασία και ενδείκνυται για παραλληλισμό. Έτσι, έχει γίνει ένα σημαντικό τυπικό παράδειγμα και πρόγραμμα σύγκρισης για τον παράλληλο προγραμματισμό. Η παράγραφος αυτή αναπτύσσει ένα παράλληλο πρόγραμμα πολλαπλασιασμού μητρών σε μια τοπολογία Τόρου σε σύστημα κατανεμημένης μνήμης. Ο σκοπός είναι η ανάλυση γενικών τεχνικών για τον επιμερισμό των δεδομένων και την δια-διεργασιακή επικοινωνία για την επίτευξη μιας καλής απόδοσης σε συστήματα κατανεμημένης μνήμης. Το παράλληλο πρόγραμμα πολλαπλασιασμού μητρών είναι πιο πολύπλοκο από το πρόγραμμα των Ν-Σωμάτων, γιατί απαιτεί δι-διάστατο πρότυπο επικοινωνίας διεργασιών. Γι’ αυτό το λόγο επιλέχτηκε η τοπολογία Τόρου για το συγκεκριμένο παράδειγμα και όχι η τοπολογία Δακτυλίου που χρησιμοποιήθηκε στο πρόγραμμα των Ν-Σωμάτων.
Για να καθορίσουμε τον πολλαπλασιασμό μητρών, ας ορίσουμε πρώτα μια λειτουργία που ονομάζεται εσωτερικό γινόμενο δύο διανυσμάτων (ένα διάνυσμα είναι απλά ένας πίνακας με μια διάσταση). Για δύο διανύσματα X=(x1, x2, ..., xn) και Y=(y1, y2, ..., yn) το εσωτερικό γινόμενο είναι:
Το εσωτερικό γινόμενο υπολογίζεται πολλαπλασιάζοντας τα αντίστοιχα στοιχεία των δύο διανυσμάτων και προσθέτοντας τα αποτελέσματα.
Τώρα ας ορίσουμε τον πολλαπλασιασμό των δύο μητρών A και B που θα παράγει τη μήτρα C. Οι μήτρες A, B, C μπορούν να αναπαρασταθούν σαν δι-διάστατοι πίνακες. Για λόγους απλότητας θεωρείστε ότι οι A και B είναι τετραγωνικές μήτρες και ότι και οι δύο έχουν διάσταση nxn. Κάθε στοιχείο Cij του γινομένου μητρών ορίζεται ως εξής:
Cij=εσωτερικό γινόμενο της γραμμής i της A με τη στήλη j της B
Έτσι, ο υπολογισμός κάθε τέτοιου στοιχείου στην μήτρα που παράγεται απαιτεί τη χρήση μιας ολόκληρης γραμμής της μήτρας A και μιας ολόκληρης στήλης της B. Από αυτόν τον ορισμό του πολλαπλασιασμού μητρών προκύπτει εύκολα ο παρακάτω ακολουθιακός αλγόριθμος:
FOR i:= 1 TO n DO (*Το i είναι ο δείκτης γραμμής*)
FOR j:= 1 TO n DO (*Το j είναι ο δείκτης στήλης*)
BEGIN
C[i, j]:= 0;
FOR k:= 1 TO n DO
(*Το εσωτερικό γινόμενο από τη γραμμή Αi και τη στήλη Βj*)
C[i, j]:= C[i, j] + A[i, k] * B[j, k];
END;
9.3.1 Επιμερισμός των μητρών
Εφόσον απαιτούνται τόσο πολλές τιμές από τις δύο μήτρες A και B για τον υπολογισμό κάθε στοιχείου της C, ο επιμερισμός στο σύστημα κατανεμημένης μνήμης πρέπει να γίνει πολύ προσεκτικά. Μια κακή μέθοδος επιμερισμού μπορεί να οδηγήσει σε εξαιρετικές απαιτήσεις δεδομένων στους επεξεργαστές. Για παράδειγμα, αν κάθε επεξεργαστής υπολογίζει μόνο μια γραμμή της μήτρας C, τότε κάθε επεξεργαστής θα χρειάζεται ένα πλήρες αντίγραφο της μήτρας B. Αν ένας επεξεργαστής υπολογίζει μια μόνο γραμμή και μια στήλη της μήτρας C τότε χρειάζεται πλήρη αντίγραφα των A και B!
Για την ελαχιστοποίηση της ποσότητας των δεδομένων που χρειάζονται σε κάθε επεξεργαστή σε ένα σύστημα κατανεμημένης μνήμης, η καλύτερη τεχνική είναι ο επιμερισμός της μήτρας C σε ένα δι-διάστατο πίνακα τετράγωνων τμημάτων, όπως φαίνεται στο σχήμα 9.7. Η nxn μήτρα διαιρείται σε έναν mxm πίνακα τετράγωνων τμημάτων, καθένα από τα οποία έχουν n2/m2 στοιχεία. Οι γραμμές και οι στήλες των τμημάτων ονομάζονται με τον τρόπο που φαίνεται στο σχήμα 9.7. Το τμήμα στην γραμμή i και τη στήλη j δηλώνεται Cij. Αυτό το πρότυπο επιμερισμού απεικονίζεται εύκολα σε μια τοπολογία Τόρου σε σύστημα κατανεμημένης μνήμης, με κάθε τμήμα να έχει ανατεθεί σε διαφορετικό επεξεργαστή. Ένας επεξεργαστής στον οποίο έχει ανατεθεί ένα τμήμα Cij είναι υπεύθυνος για τον υπολογισμό όλων των τιμών σε αυτό το τμήμα. Αυτό βέβαια απαιτεί πρόσβαση στις αντίστοιχες γραμμές και στήλες των μητρών A και B.
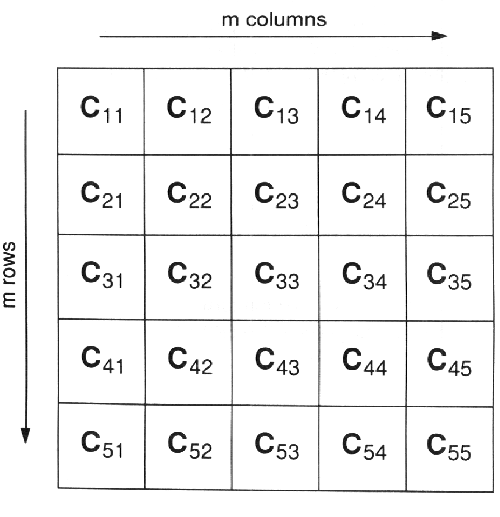
ΣΧΗΜΑ 9.7 Διαμερισμός για πολλαπλασιασμό πινάκων
Για να αναγνωρίσουμε τα μέρη που χρειάζονται από τις μήτρες A και B, ας επιμερίσουμε και τις A και B σε έναν mxm πίνακα τετράγωνων τμημάτων. Από τον ορισμό του πολλαπλασιασμού μητρών, είναι εύκολο να δείξουμε ότι ο υπολογισμός του γινομένου μητρών Cij απαιτεί όλα τα τμήματα της γραμμής i της A και της στήλης j της B. Αυτό φαίνεται στο σχήμα 9.8. Ο υπολογισμός του τμήματος C42 απαιτεί το τμήμα της γραμμής 4 της μήτρας A και το τμήμα της στήλης 2 της μήτρας B. Συνεπώς, κάθε επεξεργαστής στην τοπολογία Τόρου του συστήματος κατανεμημένης μνήμης πρέπει να έχει πρόσβαση σε μια ολόκληρη γραμμή τμήματος από την A και σε μια ολόκληρη στήλη τμήματος από τη μήτρα B.
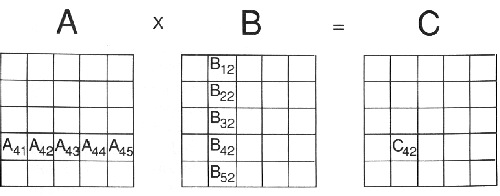
ΣΧΗΜΑ 9.8 Οι απαιτούμενες διαμερίσεις για τον πολλαπλασιασμό
Αντί να διατηρούμε αντίγραφα δεδομένων από τις δύο μήτρες A και B τα τμήματα χωρίζονται στους επεξεργαστές του Τόρου με τον ίδιο τρόπο όπως και στην μήτρα C. Για τον επιμερισμό 5x5 που παρουσιάζεται στα σχήματα 9.7 και 9.8 χρειάζεται μια τοπολογία Τόρου 5x5. Ο επεξεργαστής Pij στον Τόρο θα ανατεθεί στα τμήματα Aij, Bij και Cij. Με αυτή τη διαίρεση των τμημάτων, κάθε επεξεργαστής αρχικά έχει μόνο ένα μέρος των δεδομένων που χρειάζεται να υπολογίσει το τμήμα του της μήτρας C. Αν κοιτάξουμε προσεκτικά το σχήμα 9.8 θα δούμε ότι κάθε επεξεργαστής Pij χρειάζεται πρόσβαση σε όλα τα τμήματα της A που έχουν ανατεθεί στη στήλη i του Τόρου και σε όλα τα B τμήματα που έχουν ανατεθεί στη στήλη j του Τόρου. Στο σχήμα 9.8 ο επεξεργαστής P42 υπολογίζει το C42 και συνεπώς χρειάζεται πρόσβαση σε όλα τα A τμήματα στη γραμμή 4 και σε όλα τα B τμήματα στη στήλη 2.
Τα δεδομένα που χρειάζεται κάθε επεξεργαστής του παρέχονται από περιστροφές γραμμής και στήλης των τμημάτων των A και B. Τα τμήματα της A περιστρέφονται οριζόντια σε όλους τους επεξεργαστές στη συγκεκριμένη γραμμή. Όμοια, τα τμήματα της B περιστρέφονται κάθετα σε όλους τους επεξεργαστές στη συγκεκριμένη στήλη. Στο σχήμα 9.8 η κάθετη περιστροφή της A σημαίνει ότι ο επεξεργαστής P42 θα έχει τελικά πρόσβαση στα A41, A42, A43, A44 και A45. Όμοια, η κάθετη περιστροφή της B σημαίνει ότι ο επεξεργαστής P42 θα αποκτήσει τελικά πρόσβαση στα B12, B22, B32, B42 και B52. Αυτή η περιστροφή των τμημάτων είναι όμοια με τα περιστρεφόμενα τμήματα που χρησιμοποιούνται στο πρόγραμμα των Ν-Σωμάτων για την επιβεβαίωση ότι κάθε επεξεργαστής θα λάβει τελικά όλα τα τμήματα. Η κίνηση των δεδομένων στον Πολλαπλασιασμό Μήτρας είναι περισσότερο πολύπλοκη και απαιτεί ένα δι-διάστατο πρότυπο περιστροφής με A τμήματα να περιστρέφονται οριζόντια και B τμήματα να περιστρέφονται κάθετα.
9.3.2 Ο αλγόριθμος
Για να κάνουμε το πρόγραμμα περισσότερο απλό, θεωρείστε τον πολλαπλασιασμό δύο μητρών 3x3 χρησιμοποιώντας μέγεθος τμήματος ίσο με 1. Θα χρησιμοποιήσουμε μια τοπολογία Τόρου σε σύστημα κατανεμημένης μνήμης. Ο επεξεργαστής στη γραμμή i και τη στήλη j θα ονομάζεται “Επεξεργαστής ij”. Όμοια, τα αντίστοιχα στοιχεία των πινάκων A, B και C θα ονομάζονται Aij, Bij, και Cij. Η αρχική ανάθεση των δεδομένων στους επεξεργαστές του Τόρου είναι η ακόλουθη:
Επεξεργαστής 11 Επεξεργαστής 12 Επεξεργαστής 13
A11, B11, C11 A12, B12, C12 A13, B13, C13
Επεξεργαστής 21 Επεξεργαστής 22 Επεξεργαστής 23
A21, B21, C21 A22, B22, C22 A23 B23, C23
Επεξεργαστής 31 Επεξεργαστής 32 Επεξεργαστής 33
A31, B31, C31 A32, B32, C32 A33 B33, C33
Αν εξετάσουμε τον Επεξεργαστή 11, θα δούμε ότι ο υπολογισμός του C11 απαιτεί όλες τις τιμές A στη γραμμή 1 και όλες τις τιμές B στη στήλη 1, όπως φαίνεται και παρακάτω:
C11 = A11B11 + A12B21 + A13B31
Η ιδανική δομή για το πρόγραμμα είναι να εναλλάξουμε τον υπολογισμό με επικοινωνία, όπως κάναμε και στο πρόγραμμα των Ν-Σωμάτων. Με αυτόν τον τρόπο η αποθήκευση των δεδομένων που απαιτείται σε κάθε επεξεργαστή ελαχιστοποιείται και είναι δυνατή η επικάλυψη του υπολογισμού με επικοινωνία για μεγαλύτερη απόδοση. Παρατηρείστε ότι ο Επεξεργαστής 11 αρχικά περιέχει τις τιμές A11 και B11 και συνεπώς μπορεί να αρχίσει να υπολογίζει το C11 αμέσως, πολλαπλασιάζοντας A11B11 και σώζοντας το αποτέλεσμα. Αν οι τιμές A περιστρέφονται αριστερά και οι τιμές B περιστρέφονται προς τα πάνω, τότε ο Επεξεργαστής 11 θα λάβει τις τιμές A12 και B21 που μπορούν να πολλαπλασιαστούν και να προστεθούν στο προηγούμενο αποτέλεσμα για να λάβουμε το μερικό άθροισμα: A11B11 + A12B21. Μετά από μια ακόμη αριστερή περιστροφή του A και μια προς τα πάνω περιστροφή του B, ο Επεξεργαστής 11 θα έχει τις τιμές A13 και B31 οι οποίες μπορούν να πολλαπλασιαστούν και να προστεθούν στο μερικό άθροισμα για να δώσουν την τελική τιμή του C11.
Η παραπάνω αρχική εκχώρηση των τιμών μπορεί να εφαρμοστεί και στους Επεξεργαστές 22 και 33. Όμως, σκεφτείτε την περίπτωση του Επεξεργαστή 12. Ο υπολογισμός του C12 είναι ο ακόλουθος:
C12 = A11B12 + A12B22 + A13B32
Αρχικά, ο Επεξεργαστής 12 έχει τις τιμές A12 και B12 να εμφανίζονται στον υπολογισμό, αλλά σε διαφορετικές θέσεις. Έτσι, ο Επεξεργαστής 12 δεν έχει να ασχοληθεί μα κάτι και πρέπει να περιμένει για μια περιστροφή δεδομένων πριν να υπολογίσει. Όλες οι τιμές των A και B που χρειάζονται θα περιστραφούν τελικά στον Επεξεργαστή 12, αλλά θα υπάρξουν καθυστερήσεις και ο επεξεργαστής θα πρέπει επίσης να αποθηκεύσει προσωρινά κάποιες από τις τιμές. Αυτό το ίδιο πρόβλημα προκύπτει για όλους τους επεξεργαστές που δεν βρίσκονται στην κύρια διαγώνιο, συνεπώς για όλους εκτός από τους 11, 22 και 33.
Για να διορθωθεί το πρόβλημα υπάρχει μια απλή, αλλά ιδιαίτερα έξυπνη ρύθμιση που μπορεί να γίνει στην αρχική ανάθεση των τιμών στους επεξεργαστές. Αντί να ανατίθεται κάθε μέλος του A στον αντίστοιχο επεξεργαστή του Τόρου, τα στοιχεία του A αρχικά ανατίθενται χρησιμοποιώντας περιστροφή προς τα αριστερά: για τη γραμμή i της μήτρας A όλες οι τιμές αρχικά περιστρέφονται αριστερά σε i-1 βήματα. Όμοια, όλα τα στοιχεία του B αρχικά ανατίθενται χρησιμοποιώντας μια προς τα πάνω περιστροφή: για τη στήλη j της μήτρας B όλες οι τιμές αρχικά περιστρέφονται προς τα πάνω σε j-1 βήματα. Αυτός ο κανόνας περιστροφής έχει ως αποτέλεσμα την παρακάτω αρχική ανάθεση των δεδομένων στους επεξεργαστές του Τόρου:
Επεξεργαστής 11 Επεξεργαστής 12 Επεξεργαστής 13
A11, B11, C11 A12, B22, C12 A13, B33, C13
Επεξεργαστής 21 Επεξεργαστής 22 Επεξεργαστής 23
A22, B21, C21 A23, B32, C22 A21 B13, C23
Επεξεργαστής 31 Επεξεργαστής 32 Επεξεργαστής 33
A33, B31, C31 A31, B12, C32 A32, B23, C33
Με τον νέο αυτό κανόνα κάθε επεξεργαστής έχει στη διάθεσή του τιμές των A και B που μπορεί να χρησιμοποιήσει αμέσως. Στην πραγματικότητα, ο αλγόριθμος τώρα γίνεται υπερβολικά εύκολος. Κάθε επεξεργαστής πολλαπλασιάζει τις τρέχουσες τιμές του των A και B και σώζει το αποτέλεσμα. Στην συνέχεια όλες οι A τιμές περιστρέφονται αριστερά και όλες οι B τιμές περιστρέφονται προς τα πάνω. Μετά κάθε επεξεργαστής πολλαπλασιάζει τις πρόσφατες τιμές των A και B και προσθέτει αυτό το αποτέλεσμα στο μερικό άθροισμα. Μετά από μια ακόμη περιστροφή και ένα βήμα υπολογισμού, υπολογίζονται οι τελικές τιμές του C. Η διαδικασία που χρησιμοποιείται σε κάθε επεξεργαστή είναι η ακόλουθη:
VAR myA, myB, myC: REAL
i: INTEGER;
BEGIN
myC:= 0;
FOR i:= 1 TO 3 DO
BEGIN
myC:= myC + myA*myB;
send myA to neighbor processor in leftward rotation;
send myB to neighbor processor in upward rotation;
receive new myA;
receive new myB;
END;
write myC to master product array;
END;
9.3.3 Απλοποιημένη έκδοση
Για να κάνουμε πιο εύκολη την κατανόηση του προγράμματος θα παρουσιάσουμε πρώτα ένα πρόγραμμα Multi-Pascal με μέγεθος τμήματος ίσο με 1. Το πρόγραμμα φαίνεται στο σχήμα 9.9. Η αρχιτεκτονική συστήματος κατανεμημένης μνήμης που χρησιμοποιείται είναι αυτή του Τόρου 3x3. Σε κάθε επεξεργαστή ανατίθεται δύο θύρες για επικοινωνία. Οι πίνακες Achan και Bchan χρησιμοποιούνται για το σκοπό αυτό.
Η διαδικασία Multiply είναι στη ουσία η ίδια με αυτή που παρουσιάστηκε στον αλγόριθμο της προηγούμενης παραγράφου. Η διαδικασία αρχικά λαμβάνει τη θέση της (row, col) στον Τόρο και τις αρχικές τιμές της για για τα myA και myB. Για να προετοιμάσει τις περιστροφές των τιμών που θα ακολουθήσουν η διαδικασία Multiply πρώτα υπολογίζει τη θέση των γειτόνων της στις δεξιόστροφες και ανιούσες περιστροφές. Εφόσον η τοπολογία του Τόρου έχει συνδέσεις μεταξύ των απέναντι οριακών σημείων, ταιριάζει ιδανικά στις δι-διάστατες περιστροφές που πραγματοποιούνται στο πρόγραμμα. Στο κυρίως σώμα της διαδικασίας Multiply η επικοινωνία εναλλάσσεται με τον υπολογισμό κατά τη διάρκεια κάθε επανάληψης χρησιμοποιώντας μια τεχνική όμοια με αυτή του προγράμματος των Ν-Σωμάτων. Η βασική διαφορά είναι ότι στον Πολλαπλασιασμό Μήτρας αυτή η επικοινωνία κατευθύνεται προς δύο διευθύνσεις. Παρατηρείστε στο σχήμα 9.9 ότι το βήμα επικοινωνίας βρίσκεται ανάμεσα στα βήματα αποστολής και λήψης επικοινωνίας. Αυτό επιτρέπει μια επικάλυψη ανάμεσα στην επικοινωνία και τον υπολογισμό, όπως, εξηγήσαμε λεπτομερώς στο πρόγραμμα των Ν-Σωμάτων.
Στο σώμα του κυρίως προγράμματος δημιουργείται μια διεργασία για να εκτελεστεί σε κάθε έναν επεξεργαστή του 3x3 Τόρου. Στους φωλιασμένους βρόχους FOR ο δείκτης i είναι δείκτης γραμμής και ο δείκτης j είναι ο δείκτης στήλης. Εφόσον οι επεξεργαστές στον Τόρο έχουν ακολουθιακή αρίθμηση κατά σειρά γραμμής (δες το σχήμα 7.8) η έκφραση “@i*n+j” χρειάζεται για την ανάθεση κάθε διεργασίας στον κατάλληλο αριθμό επεξεργαστή. Για κάθε δημιουργούμενη διεργασία χρησιμοποιείται μια δήλωση PORT για να αναθέσει τα αντίστοιχα κανάλια από τους πίνακες Achan και Bchan. Οι διεργασίες στην πραγματικότητα δημιουργούνται από την κλήση στη διαδικασία Multiply που ακολουθεί το στοιχείο FORK.
PROGRAM Matrixmult;
ARCHITECTURE TORUS(3);
CONST n=3;
VAR A, B, C: ARRAY [0..n-1, 0..n-1] OF REAL; (*Αρχικοί πίνακες δεδομένων*)
Achan, Bchan: ARRAY [0..n-1, 0..n-1] OF CHANNEL OF REAL;
i, j: INTEGER;
PROCEDURE Multiply(row, col: INTEGER; myA, myB: REAL; VAR mainC: REAL);
VAR iter, above, left: INTEGER;
myC: REAL;
BEGIN
IF row > 0 THEN above:= row-1 ELSE above:= n-1; (*Πάνω γείτονας*)
IF col > 0 THEN left:= ol-1 ELSE left:=n-1; (*Αριστερός γείτονας*)
myC:= 0;
FOR iter:= 1 TO n DO
BEGIN
Achan[row, left]:= myA; (*Αποστολή του myA στην αριστερή περιστροφή*)
Bchan[above, col]:= myB; (*Αποστολή του myB στην ανιούσα περιστροφή*)
myC:= myC + myA*myB;
myA:= Achan[row, col]; (*Λήψη του νέου myA*)
myB:= Bchan[row, col]; (*Λήψη του νέου myB*)
END;
mainC:= myC; (*Αποστολή της τελικής τιμής στην κύρια διεργασία*)
END;
BEGIN
... (*Αρχικοποίηση των τιμών των μητρών A και B*)
FOR i:= 1 TO n-1 DO
FOR j:= 1 TO n-1 DO
FORK(@i*n+j PORT Achan[i,j]; Bchan[i,j])
Multiply(i, j, A[i, (j+i) MOD n], B[(i+j) MOD n, j], C[i,j]);
END.
ΣΧΗΜΑ 9.9 Απλοποιημένος Πολλαπλασιασμός Μητρών
Οι τέσσερις παράμετροι της διαδικασίας Multiply είναι οι αριθμοί γραμμής και στήλης και οι αρχικές τιμές για τα myA και myB. Θυμηθείτε ότι οι αρχικές τιμές της A περιστρέφονται αριστερά: η γραμμή i περιστρέφεται σε i-1 θέσεις. Αυτή η αρχικοποιημένη ανάθεση των περιστρεφόμενων τιμών πραγματοποιείται με την παράμετρο A[i, (j+1) MOD n]. Οι αρχικοποιημένες τιμές της B πρέπει να περιστραφούν προς τα πάνω: η στήλη j περιστρέφεται σε j-1 θέσεις και αυτό πραγματοποιείται με την παράμετρο B[(i+j) MOD n, j].
9.3.4 Ολοκληρωμένο Πρόγραμμα
Το απλοποιημένο πρόγραμμα του Πολλαπλασιασμού Μητρών με μέγεθος τμήματος ίσο με 1 δεν έχει καλή απόδοση γιατί το μέγεθος διεργασίας είναι πολύ μικρό. Για να ξεπεράσουμε τις επιβαρύνσεις δημιουργίας της διεργασίας και επικοινωνίας πρέπει να αυξηθεί η ποσότητα του υπολογισμού που πραγματοποιείται σε κάθε διεργασία. Αυτό πετυχαίνεται με τη χρήση μεγαλύτερων μητρών και αυξάνοντας το μέγεθος του τμήματος. Το πρόγμαμμα της Multi-Pascal που προκύπτει είναι παρόμοιο στη δομή με το απλοποιημένο πρόγραμμα του σχήματος 9.9. Όμως, ο κώδικας είναι κάπως πιο δύσκολος γιατί κάθε τμήμα είναι τώρα ένας δι-διάστατος πίνακας και όχι ένας απλός πραγματικός αριθμός. Το πλήρες πρόγραμμα φαίνεται στο σχήμα 9.10.
Για τη διευκόλυνση του επιμερισμού καθένας από τους πίνακες A, B, C είναι δομημένος σαν ένας δι-διάστατος πίνακας τμημάτων με κάθε τμήμα να είναι ένας δι-διάστατος πίνακας πραγματικών αριθμών. Παραπέμπουμε στις δηλώσεις σταθερών, τύπων και μεταβλητών στην αρχή του κυρίως προγράμματος στο σχήμα 9.10. Καθένας από τους πρωταρχικούς πίνακες A, B, C είναι ένας mxm πίνακας τμημάτων, με κάθε τμήμα να είναι ένας pxp πίνακας πραγματικών αριθμών. Τα κανάλια επικοινωνίας Achan και Bchan πρέπει επίσης να είναι κανάλια των οποίων ο τύπος στοιχείου είναι τμήμα. Στο πρόγραμμα έγινε κάθε προσπάθεια για το χειρισμό κάθε τμήματος σαν ξεχωριστή οντότητα, αποφεύγοντας έτσι τους φωλιασμένους βρόχους που καταναλώνουν πολύ χρόνο.
Το πρόγραμμα του σχήματος 9.10 είναι παρόμοιο με το απλοποιημένο του σχήματος 9.9. Η κύρια διαφορά είναι στο μέρος υπολογισμού της διαδικασίας Multiply. Για μέγεθος τμήματος 1, ο υπολογισμός αποτελείται από έναν απλό πολλαπλασιασμό και πρόσθεση:
myC:= myC + myA*myB;
Για μεγαλύτερα μεγέθη τμημάτων αυτός ο πολλαπλασιασμός και η πρόσθεση απλών πραγματικών αριθμών, πρέπει να αντικατασταθεί από πολλαπλασιασμό και πρόσθεση μήτρας. Κάθε τμήμα είναι μια pxp μήτρα πραγματικών αριθμών. Στο μέρος υπολογισμού της διαδικασίας Multiply τα τμήματα myA και myB πρέπει να πολλαπλασιαστούν χρησιμοποιώντας τον πολλαπλασιασμό μητρών και μετά το αποτέλεσμά τους να προστεθεί στο τμήμα myC χρησιμοποιώντας την πρόσθεση μητρών. Σύμφωνα με την επιμεριστική ιδιότητα του πολλαπλασιασμού μητρών ότι οι μήτρες μπορούν να επιμεριστούν και να πολλαπλασιαστούν με αυτόν τον τρόπο. Ο ίδιος αλγόριθμος πολλαπλασιασμού μητρών μπορεί να εφαρμοστεί στα τμήματα σαν να ήταν απλοί αριθμοί. Η μόνη διαφορά είναι ότι οι συνηθισμένες λειτουργίες του πολλαπλασιασμού και της πρόσθεσης απλών αριθμών αντικαθίστανται από τον πολλαπλασιασμό και την πρόσθεση τμημάτων μητρών. Αυτή η σημαντική ιδιότητα του πολλαπλασιασμού μητρών αναλύεται περισσότερο στις ασκήσεις του κεφαλαίου.
Ένα ενδιαφέρον χαρακτηριστικό του προγράμματος είναι η χρήση του τελεστή FORK για τη δημιουργία των διεργασιών. Βέβαια αντί γι΄ αυτό κάποιος μπορεί να μπει στον πειρασμό να χρησιμοποιήσει το ακόλουθο φωλιασμένο FORALL:
FORALL i:= 1 TO m-1 DO
FORALL j:= 1 TO m-1 DO
(@... PORT ...)
Multiply(i,j, A[...], B[...], C[...]);
PROGRAM Matrixmult;
ARCHITECTURE TORUS(7);
CONST m= 7; (*Ο Τόρος έχει mxm επεξεργαστές*)
p= 5; (*Το μέγεθος του τμήματος είναι pxp*)
TYPE partition= ARRAY [1..p, 1..p] OF REAL;
chantype= CHANNEL OF partition;
VAR A, B, C: ARRAY [0..m-1, 0..m-1] OF partition; (*Αρχικοί πίνακες δεδομένων*)
Achan, Bchan: ARRAY [0..m-1, 0..m-1] OF chantype; (*Επικοινωνία*)
i, j: INTEGER;
PROCEDURE Multiply(row,col:INTEGER; myA,myB: partition; VAR mainC: partition);
VAR i, j, k, iter, above, left: INTEGER;
myC: partition;
BEGIN
IF row > 0 THEN above:= row-1 ELSE above:= m-1;
IF col > 0 THEN left:= col-1 ELSE left:= m-1;
FOR i:= 1 TO p DO
FOR j:= 1 TO p DO
myC[i,j]:= 0;
FOR iter:= 1 TO m DO
BEGIN
Achan[row,left]:= myA; (*Αποστολή του myA στην αριστερή περιστροφή*)
Bchan[above,col]:= myB; (*Αποστολή του myB στην ανιούσα περιστροφή*)
FOR i:= 1 TO p DO (*Πολλαπλασιασμός των Α και Β τμημάτων*)
FOR j:= 1 TO p DO
FOR k:= 1 TO p DO
myC[i,j]:= myC[i,j]+myA[i,k]*myB[k,j];
myA:= Achan[row,col] (*Λήψη του νέου myA*)
myB:= Bchan[row,col] (*Λήψη του νέου myB*)
END;
mainC:= myC; (*Εγγραφή του αποτελέσματος πίσω στην αρχική C*)
END;
BEGIN
... (*Αρχικοποίηση των τιμών για τις μήτρες A και B*)
FOR i:= 0 TO m-1 DO
FOR j:= 0 TO m-1 DO
FORK(@i*m+j PORT Achan[i,j];Bchan[i,j])
Multiply(i, j, A[i, (j+i) MOD m], B[(i+j) MOD m, j], C[i,j]);
END.
ΣΧΗΜΑ 9.10 Πολλαπλασιασμός Μήτρας σε Τόρο
Αυτή η φωλιασμένη δομή FORALL δεν παράγει το επιθυμητό αποτέλεσμα εξαιτίας της δυναμικής της δήλωσης FORALL. Το εξωτερικό FORALL με το δείκτη i θα δημιουργήσει m διεργασίες, καθεμία από τις οποίες θα αποτελείται από το εσωτερικό FORALL. Αυτό το πρώτο σύνολο των m διεργασιών θα δημιουργήσουν m επιπλέον διεργασίες καλώντας τη διαδικασία Multiply. Το πρόβλημα είναι ότι το πρώτο σύνολο των m διεργασιών που βασίζονται στον δείκτη i θα ανατεθούν σε νέους επεξεργαστές για εκτέλεση. Όμως, οι πρωταρχικές μήτρες Α και Β είναι τοπικές για την διεργασία 0. Έτσι, όταν οι μήτρες Α και Β αναφέρονται στην κλήση της διαδικασίας Multiply θα έχουμε ως αποτέλεσμα μια παράνομη και μη-τοπική αναφορά πίσω στους πίνακες Α και Β. Γενικά συστήνεται στους προγραμματιστές της Multi-Pascal να αποφεύγουν τις φωλιασμένες FORALL δηλώσεις όταν γράφουν προγράμματα με επιμερισμό δεδομένων σε συστήματα κατανεμημένης μνήμης. Όμως, όπως φαίνεται στο πρόγραμμα των Ν-Σωμάτων του σχήματος 9.4 απλές μη-φωλιασμένες FORALL δηλώσεις είναι ιδιαίτερα χρήσιμες.
9.3.5 Ανάλυση απόδοσης.
Για να αναπτύξουμε μια γενική αλγεβρική έκφραση για τον συνολικό χρόνο εκτέλεσης του προγράμματος, ας καθορίσουμε τα ακόλουθα σύμβολα:
n διάσταση των μητρών
m αριθμός των γραμμών και των στηλών στον Τόρο
k αριθμός των γραμμών και των στηλών σε κάθε τμήμα
D βασική καθυστέρηση επικοινωνίας στον Τόρο
C χρόνος δημιουργίας της διεργασίας
Η γενική ανάλυση της απόδοσης του προγράμματος είναι παρόμοια με την ανάλυση του προγράμματος των Ν-Σωμάτων. Κάθε επανάληψη έχει μια φάση υπολογισμού και μια φάση επικοινωνίας. Η φάση υπολογισμού υπερέχει από τον πολλαπλασιασμό μήτρας των τμημάτων Α και Β. Αυτό γίνεται με τρεις φωλιασμένους βρόχους καθένα από τα οποία επαναλαμβάνεται k φορές. Έτσι, η διάρκεια τη φάσης υπολογισμού κατά τη διάρκεια κάθε επανάληψης έχει την ακόλουθη μορφή:
Φάση επικοινωνίας: Sk3
Κατά τη διάρκεια της φάσης επικοινωνίας τα τρέχοντα τμήματα Α και Β στέλνονται στους γειτονικούς επεξεργαστές και τα νέα τμήματα διαβάζονται. Επειδή η λειτουργία αποστολής συμβαίνει πριν τη φάση υπολογισμού και η λειτουργία λήψης μετά τη φάση υπολογισμού η πραγματική υλική μετάδοση των δεδομένων επικαλύπτει τον υπολογισμό. Έτσι, αν η καθυστέρηση επικοινωνίας υλικού είναι μικρότερη από τη διάρκεια της φάσης υπολογισμού τότε δεν θα επηρεάσει το χρόνο εκτέλεσης. Χρησιμοποιώντας το μοντέλο επικοινωνίας που περιγράψαμε στο κεφάλαιο 8, ο χρόνος επικοινωνίας για ένα μήνυμα με r πακέτα είναι ο ακόλουθος:
Εφόσον κάθε τμήμα περιέχει k2 τιμές δεδομένων και αυτές ομαδοποιούνται ανά τρεις σε κάθε πακέτο, ο χρόνος επικοινωνίας είναι ο ακόλουθος:
Συγκρίνοντας την παραπάνω σχέση με το χρόνο επικοινωνίας, φαίνεται ότι ο χρόνος επικοινωνίας δεν επηρεάζει αν ικανοποιεί τη σχέση:
Χρησιμοποιώντας τη Multi-Pascal μπορούμε να καθορίσουμε ότι η σταθερά S έχει την τιμή 30. Αντικαθιστώντας την τιμή αυτή στην παραπάνω ανισότητα έχουμε:
k=1: D![]() 45
45
k=2: D![]() 205
205
k=3: D![]() 405
405
k=4: D![]() 606
606
k=5: D![]() 800
800
Η παραπάνω ανάλυση δείχνει ότι για όλα τα μεγέθη τμήματος εκτός από τα πολύ μικρά η καθυστέρηση επικοινωνίας υλικού μπορεί ουσιαστικά να αγνοηθεί στην ανάλυση απόδοσης αυτού του προγράμματος (εκτός εάν η βασική καθυστέρηση επικοινωνίας D είναι ιδιαίτερα μεγάλη). Συνεπώς η συνολική διάρκεια του υπολογιστικού μέρους του προγράμματος μπορεί να οριστεί πολλαπλασιάζοντας τη διάρκεια της φάσης υπολογισμού κάθε επανάληψης (Sk3) επί το συνολικό αριθμό m των επαναλήψεων:
Χρόνος εκτέλεσης υπολογισμού:
Ο συνολικός χρόνος εκτέλεσης είναι ο ακολουθιακός χρόνος εκτέλεσης που απαιτείται για τον πολλαπλασιασμό μήτρας (Sn3) δια του αριθμού των επεξεργαστών στην τοπολογία Τόρου (m2). Η μέγιστη επιβάρυνση που μπορεί να μειώσει την επιτάχυνση κάτω από αυτή την ιδανική τιμή δημιουργείται από τη δημιουργία της διεργασίας και την κατανομή των δεδομένων που συμβαίνουν στην αρχή του προγράμματος. Είναι ενδιαφέρον να αναλύσουμε αυτή την αρχική φάση του προγράμματος με περισσότερες λεπτομέρειες. Εφόσον υπάρχουν m2 διεργασίες ο χρόνος που απαιτείται για να δημιουργηθούν όλες είναι:
Χρόνος δημιουργίας της διεργασίας: Cm2
Καθώς όλες αυτές οι διεργασίες δημιουργούνται αποστέλλονται με τα αρχικά τμήματα δεδομένων στους φυσικούς επεξεργαστές. Ο χρόνος που απαιτείται για αυτή την επικοινωνία στην τοπολογία του Τόρου είναι δύσκολο να υπολογιστεί αναλυτικά. Όμως, μπορούμε να αναπτύξουμε μια απλοποιημένη προσέγγιση. Εφόσον και οι δύο πίνακες Α και Β κατανέμονται στους επεξεργαστές, η συνολική ποσότητα των δεδομένων που κατανέμονται είναι 2n2 που είναι αποτέλεσμα των 2n2/3 πακέτων επικοινωνίας. Το κύριο σημείο συμφόρησης σε αυτή την κατανομή προέρχεται από την κατανομή πακέτων από τον επεξεργαστή 0 ο οποίος έχει τέσσερις μόνο συνδέσμους. Στην μέθοδο δρομολόγησης που χρησιμοποιείται στην Multi-Pascal τα πακέτα συνεχώς κινούνται οριζόντια πρώτα. Με αυτόν τον τρόπο η μεγαλύτερη πλειονότητα των πακέτων θα συγκεντρωθεί στους δύο οριζόντιους συνδέσμους από τον επεξεργαστή 0. Κάθε πακέτο κρατάει ένα σύνδεσμο απασχολημένο για D/2 χρόνο. Έτσι, ο συνολικός χρόνος για τη μετακίνηση όλων των πακέτων κατά μήκος των δυο οριζόντιων συνδέσμων είναι:
Όλα αυτά τα δεδομένα στέλνονται σταδιακά στο δίκτυο επικοινωνίας καθώς οι διεργασίες δημιουργούνται. Κάθε κλήση διαδικασίας που δημιουργεί μια διεργασία στέλνει επίσης τα τμήματα δεδομένων που της έχουν ανατεθεί στο δίκτυο. Έτσι, αυτή η κατανομή των δεδομένων επικαλύπτει τη δημιουργία της διεργασίας. Η συνολική διάρκεια αυτής της αρχικής φάσης είναι η μέγιστη τιμή των παρακάτω:
Αρχική φάση:
Όταν η βασική καθυστέρηση επικοινωνίας D είναι μικρή, θα κυριαρχήσει ο όρος δημιουργίας της διεργασίας. Καθώς η τιμή D αυξάνεται θα αγγίξει ένα σημείο καμπής, μετά το οποίο θα κυριαρχήσει ο χρόνος κατανομής των δεδομένων. Το σημείο καμπής μπορεί να υπολογιστεί εξισώνοντας τους δύο χρόνους και λύνοντας ως προς D, όπως φαίνεται παρακάτω:
Και συνεπώς,
Αντικαθιστώντας n=mk έχουμε το ακόλουθο σημείο καμπής:
Το σχήμα 9.11 δείχνει ένα γράφημα της πραγματικής απόδοσης του προγράμματος Πολλαπλασιασμού Μήτρας για ένα σύνολο τιμών του k, της διάστασης του τμήματος. Όπως και με όλα τα γραφήματα απόδοσης σε αυτό το κεφάλαιο, αυτό το γράφημα δημιουργήθηκε χρησιμοποιώντας το σύστημα της Multi-Pascal με την επιλογή συμφόρησης ενεργή. Ο κάθετος άξονας είναι η επιτάχυνση που επιτυγχάνεται από το πρόγραμμα. Ο αριθμός των επεξεργαστών στην τοπολογία του Τόρου διατηρείται σταθερό στους 49 για όλες τις τιμές του k. Έτσι, το ανώτερο όριο που μπορεί να επιτευχθεί στην επιτάχυνση είναι 49. Ο οριζόντιος άξονας είναι η βασική καθυστέρηση επικοινωνίας D. Τα δύο σημαντικότερα χαρακτηριστικά της απόδοσης του προγράμματος μπορούν να παρατηρηθούν στο γράφημα. Πρώτα, ανεξάρτητα από την τιμή του k το γράφημα είναι σχετικά επίπεδο στην αριστερή του πλευρά. Δεύτερο, καθώς το D αυξάνεται, προσεγγίζεται ένα σημείο καμπής μετά το οποίο η επιτάχυνση σταδιακά μειώνεται. Αυτό επιβεβαιώνει την ορθότητα της ανάλυσης στην οποία εντόπισε αυτό το σημείο καμπής.
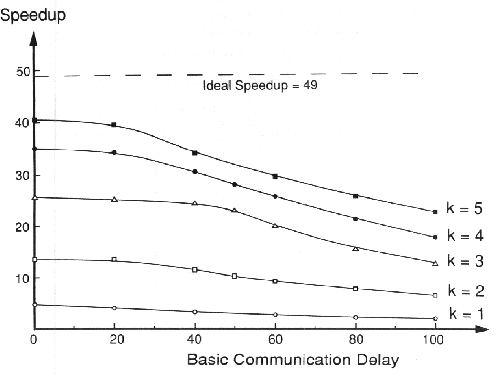
ΣΧΗΜΑ 9.11 Επιτάχυνση στον πολλαπλασιασμό πινάκων
Στην αριστερή πλευρά κάθε γραφήματος ο χρόνος δημιουργίας της διεργασίας είναι η κυρίαρχη επιβάρυνση. Στο δεξιό μέρος του γραφήματος η καθυστέρηση επικοινωνίας για την κατανομή των δεδομένων είναι η κυρίαρχη επιβάρυνση. Όμως, είναι ενδιαφέρον ότι και στις δύο περιοχές η επιτάχυνση που επιτυγχάνεται αυξάνεται καθώς αυξάνεται και το k. Αυτό συμβαίνει γιατί το υπολογιστικό μέρος του προγράμματος έχει χρόνο εκτέλεσης O(k3), ενώ ο χρόνος δημιουργίας της διεργασίας είναι σταθερός για όλες τις τιμές του k και ο χρόνος κατανομής δεδομένων είναι O(k2). Έτσι, αυξάνοντας το k θα μειωθεί η επίδραση της επιβάρυνσης και στην αριστερή και στη δεξιά περιοχή. Αυτό είναι ένα συγκεκριμένο παράδειγμα της γενικής ιδιότητας που αναφέρθηκε στα προηγούμενα κεφάλαια ότι οι επιβαρύνσεις αρχικοποίησης και δημιουργίας της διεργασίας μπορούν να ξεπεραστούν αυξάνοντας το μέγεθος των δεδομένων για τον ίδιο αριθμό επεξεργαστών.
![]()
![]()
![]()
![]()
Επόμενο:9.4 Αλγόριθμος JACOBI Πάνω: Κεφάλαιο 9o : Επιμερισμός δεδομένων Πίσω: 9.2 Το Πρόβλημα των Ν-Σωμάτων στην Αστροφυσική