Art of Assembly: Κεφαλαιο 3
Η παράλληλη εκτέλεση εντολών η οποία χρησιμοποιεί μια μονάδα διεπαφής διαύλου (bus interface unit) και μια εκτελέσιμη μονάδα είναι μια ειδική περίπτωση χρήσης pipeline (σωλήνωσης) . Ο 8486 εμπεριέχει pipelining για να αυξήσει την απόδοση.
Το πλεονέκτημα της ουράς προ-ανάκλησης ήταν ότι άφηνε στην CPU να εκτελεί
παράλληλα εντολές ανάκλησης και αποκωδικοποίησης με εντολές εκτέλεσης.
Αυτό σημαίνει , ότι καθώς μια εντολή εκτελείται, το BIU ανακαλείται και
αποκωδικοποιεί την επόμενη εντολή. Ας υποθέσουμε ότι επιθυμείς να προσθέσεις
hardware. Μπορείς να εκτελείς όλες σχεδόν τις διαδικασίες σε παραλληλία.
Αυτή είναι η ιδέα που κρύβεται πίσω από την σωλήνωση.
Σκέψου τα αναγκαία βήματα για να φτιάξεις μια γενετική εφαρμογή.
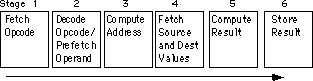
Αν σχεδιάζεις ένα ξεχωριστό κομμάτι του hardware σε κάθε επίπεδο στην
παραπάνω σωλήνωση , σχεδόν όλα αυτά τα βήματα μπορούν να πραγματοποιηθούν
παράλληλα. Φυσικά, δεν μπορείς να ανακαλείς και να αποκωδικοποιείς τον
κωδικό εντολής (opcode) για κάθε μια εντολή ταυτόχρονα , αλλά μπορείς
να ανακαλέσεις τον κωδικό μιας εντολής καθώς αποκωδικοποιείς την προηγούμενη
εντολή. Ο 8486 επεξεργαστής έχει έξι επιπέδων σωλήνωση και μπορεί και επεξεργάζεται
ταυτόχρονα έξι διαφορετικές εντολές.
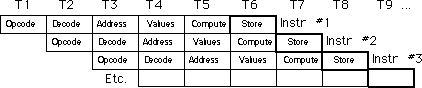
3.3.11.2. Μποτιλιάρισμα σωλήνωσης (σωλήνωση)
Δυστυχώς , το σενάριο που παρουσιάστηκε παραπάνω είναι αρκετά απλοποιημένο. Υπάρχουν δυο μειονεκτήματα σ’ αυτήν την απλοϊκή σωλήνωση: το μποτιλιάρισμα του διαύλου κατά των εντολών και η μη-διαδοχική εκτέλεση του προγράμματος. Και τα δυο προβλήματα θα αυξήσουν τον μέσο χρόνο εκτέλεσης των εντολών μέσα στην σωλήνωση.
To μποτιλιάρισμα διαύλου συμβαίνει όταν μια εντολή χρειάζεται να προσπελάσει κάποιες εγγραφές στην μνήμη. Π.χ. αν μια εντολή «mov mem, reg» χρειάζεται να αποθηκεύσει δεδομένα στην μνήμη και μια εντολή «mov reg, mem» διαβάζει δεδομένα από τη μνήμη, το μποτιλιάρισμα για την διεύθυνση και την δίαυλο δεδομένων μπορεί να αναπτυχθεί καθώς η CPU θα προσπαθεί να ανακαλέσει δεδομένα και ταυτόχρονα να γράφει δεδομένα στην μνήμη.
Ένας απλοϊκός τρόπος να χειρίζεσαι μποτιλιάρισμα διαύλου είναι μέσω
ενός μποτιλιαρίσματος σωλήνωσης . Η CPU , όταν συναντά ένα μποτιλιάρισμα
διαύλου, δίνει προτεραιότητα στην εντολή που βρίσκεται πιο μέσα στην σωλήνωση.
Η CPU προβλέπει κωδικούς ανάκλησης εντολών μέχρι η τρέχουσα εντολή να ανακαλέσει
(ή να αποθηκεύσει) τα τελούμενα της. Αυτό επιβάλει στην νέα εντολή μέσα
στην σωλήνωση να χρειάζεται δυο κύκλους για να εκτελεστεί αντί για έναν.
Αυτό είναι ένα παράδειγμα μποτιλιαρίσματος διαύλου.
3.3.11.3. Cache, Ουρά Προ-ανάκλησης και ο 8486.
Οι σχεδιαστές συστημάτων μπορούν να επιλύσουν προβλήματα μποτιλιαρίσματος του διαύλου μέσω της έξυπνης χρήση της ουράς προ-ανάκλησης και του υποσυστήματος της κρυφής μνήμης. Μπορούν να σχεδιάσουν την ουρά προ-ανάκλησης για να καταφέρουν προσωρινή αποθήκευση δεδομένων από το τμήμα των εντολών και μπορούν να σχεδιάζουν την cache με ξεχωριστές περιοχές δεδομένων και κωδικών. Και οι δυο τεχνικές μπορούν να αυξήσουν την απόδοση του συστήματος, εξαλείφοντας κάποιες συγκρούσεις για την δίαυλο.
Η ουρά προ-ανάκλησης, απλούστατα, λειτουργεί ως προσωρινός απομονωτής(buffer) μεταξύ του τμήματος εντολών στην μνήμη και του κώδικα εντολής του κυκλώματος ανάκλησης. Δυστυχώς , η ουρά προ-ανάκλησης στον 8486 δεν έχει το πλεονέκτημα που είχε στο 8286. Η ουρά προ-ανάκλησης δουλεύει καλύτερα για τον 8286, γιατί η CPU δεν προσπελαύνει συνεχώς την μνήμη. Όταν η CPU δεν κάνει αυτό, η BIU μπορεί να ανακαλέσει επιπρόσθετους κωδικούς εντολής για την ουρά προ-ανάκλησης. CPU του 8486 διαρκώς προσπελαύνει την μνήμη, μέχρι να ανακαλέσει ένα byte κώδικα εντολής σε κάθε κύκλο ρολογιού. Όμως η ουρά προ-ανάκλησης δεν μπορεί να εκμεταλλευτεί κανένα «νεκρό» κύκλο διαύλου για να ανακαλέσει επιπρόσθετα bytes κώδικα εντολής - δεν υπάρχουν νεκροί κύκλοι διαύλου. Παρόλα αυτά , η ουρά προ-ανάκλησης είναι χρήσιμη στον 8486 για ένα πολύ απλό λόγο : το BIU ανακαλεί δυο bytes σε κάθε προσπέλαση μνήμης, ακόμη και αν ορισμένες εντολές έχουν 1 byte μήκος. Χωρίς την ουρά προ-ανάκλησης, το σύστημα θα έπρεπε να ανακαλεί με σαφή τρόπο κάθε opcode, ακόμη και αν η BIU είχε ήδη «συμπτωματικά» ανακαλέσει τον opcode με την προηγούμενη εντολή. Με την ουρά προ-ανάκλησης όμως, το σύστημα ανακαλεί τους κωδικούς εντολών μια φορά και τα αποθηκεύει για να χρησιμοποιηθούν από την μονάδα ανάκλησης opcode .
Υπέθεσε, για μια στιγμή, ότι η CPU έχει δυο ξεχωριστούς χώρους μνήμης,
έναν για τις εντολές και ένα για τα δεδομένα, το καθένα με το δικό τους
δίαυλο. Αυτό ονομάζεται Harvard Architecture μια και η πρώτη τέτοιου είδους
μηχανή δημιουργήθηκε στο Harvard. Σ’ αυτό δεν υπάρχουν μποτιλιαρίσματα
διαύλου. Το BIU θα συνεχίσει να ανακαλεί opcodes στην δίαυλο δεδομένων
καθώς προσπελαύνει την μνήμη στην δίαυλο δεδομένων/ μνήμης.
Στο πραγματικό κόσμο, υπάρχουν πολύ λίγες μηχανές Harvard. Οι έξτρα
ακροδέκτες που απαιτούνται να υπάρχουν στον επεξεργαστή για να υποστηρίξει
δυο ξεχωριστούς διαύλους, αυξάνει το κόστος του επεξεργαστή και εισάγει
πολλά άλλα τεχνικά προβλήματα. Οι σχεδιαστές μικροεπεξεργαστών έχουν ανακαλύψει
ότι μπορούν να εξασφαλίσουν πολλά πλεονεκτήματα από την αρχιτεκτονική αυτή,
μαζί με λίγα μειονεκτήματα, χρησιμοποιώντας ξεχωριστές (κρυφές) μνήμες
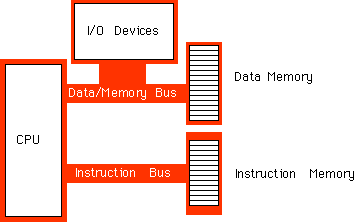
μέσα στο chip για δεδομένα και εντολές. Το παρακάτω σχήμα δείχνει την δομή
ενός 8486 με ξεχωριστές cache για δεδομένα και εντολές.
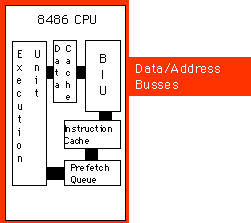
Κάθε μονοπάτι μέσα στην CPU αναπαριστά ένα ανεξάρτητο δίαυλο. Τα δεδομένα μπορούν να ρέουν σ’ όλα τα μονοπάτια ταυτοχρόνως, Αυτό σημαίνει ότι η ουρά προ-ανάκλησης μπορεί να ανακαλέσει τους κωδικούς εντολών από την κρυφή μνήμη εντολών, καθώς η μονάδα εκτέλεσης γράφει δεδομένα στην cache δεδομένων. Τώρα η BIU ανακαλεί opcodes μόνο από την μνήμη όταν δεν μπορεί να τα εντοπίσει στην cache δεδομένων. Παρομοίως, η κρυφή μνήμη δεδομένων αποθηκεύει- καταχωρεί μνήμη. Η CPU χρησιμοποιεί δίαυλο δεδομένων / διευθύνσεων μόνο όταν διαβάζει μια τιμή , η οποία δεν είναι μέσα στην cache ή όταν ρέουν δεδομένα πίσω στην κύρια μνήμη.
Αν και δεν είναι δυνατό να ελέγχεις την μορφή, το μέγεθος ή τον τύπο
της cache στην CPU ως προγραμματιστής γλώσσας assembly θα πρέπει να γνωρίζεις
πώς λειτουργεί η cache για να φτιάξεις το καλύτερο πρόγραμμα. Οι λανθάνουσες
(κρυφές) μνήμες εντολών μέσα στο chip είναι γενικά αρκετά μικρές (8,192
bytes στον 80486). Παρόλα αυτά, όσο μικρότερες είναι οι εντολές σου, τόσο
περισσότερες θα χωράνε στην cache. Όσο περισσότερες εντολές έχεις στην
cache, τόσο σπανιότερα θα παρουσιάζονται μποτιλιαρίσματα διαύλου. Παρόμοια,
χρησιμοποιώντας καταλόγους για να κρατάς προσωρινά αποτελέσματα, προσφέρεις
λιγότερη δουλειά στην κρυφή μνήμη δεδομένων, έτσι ώστε να μην χρειάζεται
να ρέουν δεδομένα στην μνήμη ή να ανακτάς δεδομένα από την μνήμη τόσο συχνά.
Να χρησιμοποιείς καταχωρητές όπου αυτό είναι δυνατό .
3.3.11.4. Κίνδυνοι στους 8486.
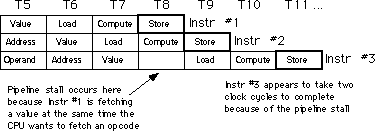
Υπάρχει ακόμη ένα πρόβλημα που πηγάζει από την χρησιμοποίηση μιας σωλήνωσης: O κίνδυνος ενημέρωσης δεδομένων. Ας ρίξουμε μια ματιά στον τρόπο εκτέλεσης των παρακάτω διαδοχικών εντολών:
mov bx, [1000]
mov ax, [bx]
Όταν αυτές οι δυο εντολές εκτελούνται, η pipeline θα έχει την εξής μορφή:
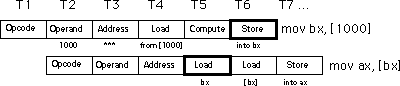
Σημειώστε ένα τεράστιο πρόβλημα εδώ. Αυτές οι δυο εντολές προσκομίζουν
την 16-bit τιμή της οποίας η διεύθυνση εμφανίζεται στην θέση 1000 στην
μνήμη. Αλλά αυτή η αλληλουχία εντολών δεν θα δουλέψει σωστά. Δυστυχώς,
η δεύτερη εντολή έχει ήδη χρησιμοποιήσει την τιμή στο bx πριν η πρώτη εντολή
να φορτώσει τα περιεχόμενα της θέσης μνήμης 1000 (Τ4 και Τ6 στο παραπάνω
διάγραμμα). Οι CISC επεξεργαστές, όπως και οι 80x86 αντιμετωπίζουν τους
κινδύνους αυτόματα. Παρόλα αυτά θα χρονοτριβήσουν την pipeline για να συγχρονίσει
αυτές τις δυο εντολές. Η πραγματική εκτέλεση σ' έναν 8486 θα έμοιαζε με
το παρακάτω :
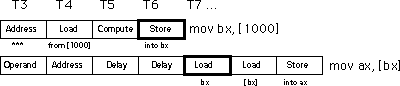
Καθυστερώντας την δεύτερη εντολή κατά δυο κύκλους ρολογιού, ο 8486 εγγυάται ότι η εντολή φόρτωσης θα φορτώσει ax από την κατάλληλη διεύθυνση. Δυστυχώς η δεύτερη εντολή φόρτωσης τώρα εκτελείται σε τρεις κύκλους ρολογιού αντί σε έναν. Βέβαια, η απαίτηση δυο έξτρα κύκλων ρολογιού είναι καλύτερη από την παραγωγή λάθος αποτελεσμάτων. Ευτυχώς, μπορείς να μειώσεις την πιθανότητα εμφάνισης κινδύνων μέσω του λογισμικό σου.
Με την αρχιτεκτονική της pipeline στον 8486, μπορούμε να πετύχουμε τον
καλύτερο χρόνο εκτέλεσης ανά εντολή CPI (Clock Per Instruction). Είναι
δυνατό να εκτελούμε εντολές πιο γρήγορα από αυτό; Με την πρώτη ματιά απαντάς
«Φυσικά όχι, δεν μπορούμε να εκτελούμε το περισσότερο μια διαδικασία ανά
κύκλο ρολογιού». Διευκρινίστε στο μυαλό σας όμως ότι μια μοναδική
εντολή δεν είναι το ίδιο με μια διαδικασία. Η απάντηση λοιπόν είναι ναι.
Μια CPU, συμπεριλαμβανομένου και του πρόσθετου hardware είναι μια υπερβαθμωτή
CPU και μπορεί να εκτελεί περισσότερες από μια εντολές μέσα σ’ ένα κύκλο
ρολογιού. Αυτή είναι η δυνατότητα που προσφέρει ο επεξεργαστής 8686. Μια
υπερβαθμωτή CPU έχει ουσιαστικά, αρκετές μονάδες εκτέλεσης. Αν συναντήσει
δυο ή περισσότερες εντολές στο τμήμα εντολών, αυτή που μπορεί να εκτελεστεί
ανεξάρτητα, αυτήν εκτελεί.
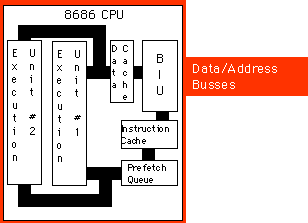
Υπάρχουν κάποια πλεονεκτήματα στην υπερβαθμωτή CPU. Υπέθεσε ότι έχεις τις παρακάτω εντολές στο τμήμα εντολών :
Mov ax, 1000
Mov bx, 2000.
Αν δεν υπάρχουν άλλα προβλήματα ή κίνδυνοι στον περιβάλλων κώδικα και τα 6 bytes για τις δυο εντολές είναι τρέχοντα στη ουρά προ-ανάκλησης, δεν υπάρχει κανένας λόγος η CPU να μην μπορεί να φέρει και να εκτελέσει και τις δυο εντολές παράλληλα. Ότι χρειάζεται είναι ένα έξτρα πυρίτιο στο τσιπ της CPU για να θέσει σε λειτουργία δυο μονάδες εκτέλεσης .
Εκτός από την επιτάχυνση των ανεξάρτητων εντολών, μια υπερβαθμωτή CPU μπορεί επίσης να επιταχύνει την αλληλουχία του προγράμματος το οποίο έχει κινδύνους- ένας περιορισμός της 8486 CPU είναι ότι όταν παρουσιάζεται κίνδυνος, η προσβληθείσα εντολή θα μπλοκάρει την pipeline. Κάθε εντολή που ακολουθεί, θα πρέπει επίσης να περιμένει ως ότου η CPU δυγχρονίσει την εκτέλεση των εντολών. Με μια υπερβαθμωτή CPU, όμως, οι εντολές που ακολουθούν τον κίνδυνο μπορεί να συνεχίσουν την εκτέλεση τους μέσω της pipeline, όσο δεν εμφανίζουν κινδύνους μέσα στο δικό τους πλαίσιο. Αυτό ελαφραίνει ορισμένες από τις ανάγκες για προσεχτικό προγραμματισμό εντολών.
Ως προγραμματιστής γλώσσας assembly, θα πρέπει να γνωρίζεις ότι ο τρόπος
που γράφεις ένα λογισμικό για μια υπερβαθμωτή CPU μπορεί να επηρεάσει δραματικά
την απόδοση της. Ο πρώτος και σημαντικότερος κανόνας είναι να χρησιμοποιείς
μικρές εντολές. Οι περισσότερες υπερβαθμωτές CPU δεν επαναλαμβάνουν ολοκληρωτικά
την ομάδα εκτέλεσης . Μπορεί να υπάρχουν πολλαπλά ALU, μονάδες κινητής
υποδιαστολής κτλ. Αυτό σημαίνει ότι μια αλληλουχία εντολών μπορεί να εκτελεστεί
πολύ γρήγορα, ενώ άλλες όχι. Θα πρέπει να μελετήσεις την σύνθεση της δικιάς
σου CPU για να αποφασίσεις ποια σειρά εντολών παράγει την καλύτερη απόδοση.
[Chapter Three][Previous] [Next] [Art of Assembly][Randall Hyde]